- 易迪拓培训,专注于微波、射频、天线设计工程师的培养
基于C语言的设计流优化语音识别芯片结构设计
录入:edatop.com 点击:
据预测,市场对语音控制应用设备的需求将急剧增长,其推动力来自电话机市场。电话机将更多地采用语音命令进行控制。其他应用领域包括玩具和手持设备如计算器、语音控制的安全系统、家用电器及车载设备(立体声、视窗、环境控制、车灯和导航控制)。本文从可复用和优化芯片空间的角度出发介绍语音识别芯片结构设计的种种考虑,其思路有利于开发一系列其它语音识别芯片。 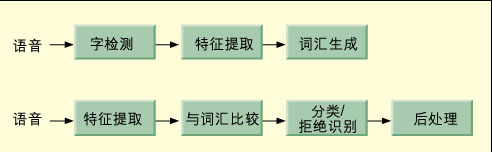 新加坡Columns公司在便携式语音控制产品应用中起步较早,其中一个产品是执行欧元与其他欧洲货币之间进行兑换的“语音控制欧洲货币兑换器”。欧元兑换器的设计要求包括:1. 功率小,电池寿命至少为1年;2. 价格低廉,产品零售价不超过9美元;3.具有很强的灵活性,能用多种语言精确地识别并合成与说话人相关的语音;4. 整个语音控制核产品应具备可复用的特性。 本文介绍利用Frontier Design公司设计工具来开发欧元兑换器ASIC产品的全过程。在ASIC中实现复杂DSP算法的要求通常极为苛刻,但采用Frontier的结构合成工具A|RT Designer工具能迅速优化RTL描述,该工具还允许自由选择备用结构以优化应用设计。 通过应用基于C语言的设计流,能在结构设计阶段对新特性进行设计和硬件优化,这能降低50%的硅片面积,通过加快 C语言原型硬件的设计,可以进一步扩展设计的性能以满足用户对产品规格的严格要求。 算法研究 欧元兑换器的效率在一定程度上取决于语音命令与存储数据库的比较以及执行命令的能力。开发出满足最终产品要求的算法对设计的成功至关重要,因为没有人希望看到语音控制设备不能始终如一地识别命令,人们需要算法自始至终达到98%以上的识别精度。因此,目前面临的难题包括检测并清除背景噪声、区分真实的命令字和其他噪声(呼吸声、微小静电干扰声及麦克风声响)、确定命令字的起始和终止以及将输入与存储的“声纹谱”数据库及随后的命令字识别(图1)进行比较。 以下几种先进的计算密集DSP算法适用于解决上述问题:1. Mel频率声谱(cepstral)系数(MFCC)算法,MFCC算法由快速傅立叶变换(FFT)功能谱、Mel定标和log ii构成;2. 反离散余弦变换(iDCT);3. 应用多重估计和选择算法连续识别并估计背景声音和语音噪声的连续噪声电平估计程序;4. 在命令字有效期间及其附近对声音能级实施详尽分析的不精确和精确命令字边界检测算法;5. 对一系列不等长度的向量进行比较并在这些向量间比较持续时间变化的动态时间扭曲算法(dynamic time warp)。 该算法用浮点C语言编程,为了调整并优化参数,浮点C代码的编译和仿真速度要足够快以检验算法的性能。最后,C语言代码必须能在传统的PC机上运行,语音识别和合成算法的性能可在实际环境中进行测试。最终的语音识别算法在450MHz奔腾机上测试,当用该公司的内部语音记录库进行测试时,可得到99%的识别精度。 [b]浮点算法向定点算法转换 [/b] 芯片实现需要将浮点算法转换为定点算法,要保证动态范围和精度并防止转换后超越动态极限。常规定点操作数的非优化范围可能导致操作数绕回(wrap around, 如(max+1)得到(min)),并引发严重的削波和误码。定点的精确度同等重要,特别是在重复的信号处理运算中。当精确度不够时,重复的信号处理算法将导致故障传播和错误累积,最终信号可能逐渐退化成白噪声,这对于语音控制产品来说无疑是灾难性的错误。 Frontier工具拥有一个称为A|RT库的C++类库,它是分析C代码定点性能的工具。该类库支持多种定点数据类型,对多重溢出行为(如饱和和绕回)提供位真建模(bit-true modeling),并提供截断和舍入零等多重量化模型。原始的32位浮点语音识别算法支持数据以8 KHz输入,其典型信号带宽为32位,内存容量要求为几千字节,典型语音用户接口的输出以每秒几字节的速率测量。 代码合并实现最终产品 分析表明,全局数据类型(global data-type)和数组只需16位(1个符号位,10个动态位,5个精度位)就足以保持算法的精度,而不会产生噪声。但是,高度重复性的FFT子程序需要8个动态位、7个精度位以及1个符号位。通常这种分析可用全局使用的19位字宽满足任何操作的动态位和精度位的最大要求。由于A|RT库允许字宽动态改变,而全局数据类型定义了1个符号位、10个动态位和5个精度位,FFT的MAC结果分配了1个符号位、8个动态位和5个精度位,因此设计的字宽(包括总线)保持为16位。这样可大大节省硅片面积。 完成定点C算法转换后,就可用常规C++编译器编译C代码,并在PC机上运行(也可在HP或SUN机器上运行)。所有信号的位真定义(bit-true definition)保证了硬件映射的正确索引以及到其他数字部件如HDL编译器和仿真器的直接接口。将定点识别代码与欧元兑换器应用程序的C代码合并,就可得到完整的可执行最终代码。 系统设计的考虑 为了达到成本目标,单片SoC解决方案是唯一可行的方案。SoC必须将如下资源集成至不超过25,000门的芯片上:1. 语音识别与合成(SRS)识别核;2. 语音识别与合成(SRS)程序和欧元兑换器代码(最大30KB);3. 语音合成实例(最大30KB);4. 用于存储声纹(voice print)并用作中间结果存储器的RAM(最大30K字节);5. AD/DA转换器;6. 麦克风接口;7. 扬声器接口。 功耗也是要考虑的重要问题,电池寿命至少应为1年半。要满足这些苛刻的功率要求,系统必须具备省电模式、在RAM中存储声纹、处理器具有较低的时钟频率以及高效率的音频放大器。 SRS处理器结构 要给定所必需的处理和低功耗约束条件,选择目标时钟频率是首要任务。根据对初始功耗和处理计算的估计,我们认为2到4MHz时钟频率足以满足要求。选择3.579 MHz是因为该频率是NTSC视频系统的基础,而石英成本低廉。 该算法需要检测并去除背景噪声。为了从奔腾机的450MHz时钟得到3.5MHz时钟,并保持芯片核门数小于25,000,SRS要采用专用结构。 设计专用处理器费时费力,要用HDL语言重写算法以获得最佳方案。A|RT Designer工具综合了基于控制器的结构,并直接以高效能的C语言算法为基础。设计工程师通过分析和优化,然后转化为Verilog或VHDL代码。 设计工程师使用A|RT Designer工具为语音识别算法合成适当的结构,之后进行RTL描述。该工具分配必需的数据通路资源(乘法器、加法器、ALU、I/O、RAM、ROM等),为这些资源分配算术运算,并对运算过程进行调度。同时将自动生成一个控制器、微代码(用来控制资源分配和调度)及寄存器、多路转换器和总线。 将SRS算法映射到硬件结构的关键参数是:以3.5MHz目标时钟频率运行完整的SRS代码,且不超过最大25,000门的约束条件。使用A|RT Designer的“负载视图(load view)”,设计工程师识别出代表性能瓶颈的几个多周期运算(multiple cycle operation)。视图上出现瓶颈的位置将显示相关C代码,设计工程师因而能识别产生瓶颈的原因并试验备选解决方案。 最明显的瓶颈是MEL运算中的密集FFT计算,它占据了实时处理周期80%的时间。通过增加一个二级加法器和专用地址计算单元ACU (address calculation unit),FFT就能优化到只占原始运算周期的10%。这虽然增加了硬件设备,但付出的代价只是4,000个门,正好在硬件预算以内。即便如此改进,所用周期的总数目实在太高,难以达到3.5MHz的时钟频率。 进一步分析表明,可以改进对数函数的计算。当在RISC DSP (NSC CR16B)上运行C语言算法时,该运算占用大约1,000个周期,约为实时运算需求的15%。添加专用的特定应用单元ASU (application specific unit)进一步将这些功能的循环周期降至3个周期,而只增加200个门。上述结构上的改变使最小时钟频率为1.5MHz,少于目标频率的一半。 对门电路数目和语音识别核功耗的优化可以降低寄存器触发器的数目。触发器的开销很大(每个需要10个门电路),并消耗很大的功率。A|RT Designer的“寿命视图(life-time view)”用来分析组成每个变量寿命的周期数目及变量被使用的频率。通过在RAM中存储不常使用但长期有效的变量,即可降低寄存器的总数,进一步减小所需的硅片面积和功率。该措施节约了50%的寄存器门电路,同时为运算周期预算留下充足的开销空间。 RAM压缩的实现 在设计初期,我们已经明确30KB的RAM空间太紧张。参考SRS C代码的每个声纹谱(约为1秒钟的语音)字占用大约1-2KB,相当于30条命令,这样几乎没给中间结果SRAM留下任何空间。由于30KB的RAM占用了硅片相当大的面积,因此在硅片预算中无法添加更多的RAM(图2)。
新加坡Columns公司在便携式语音控制产品应用中起步较早,其中一个产品是执行欧元与其他欧洲货币之间进行兑换的“语音控制欧洲货币兑换器”。欧元兑换器的设计要求包括:1. 功率小,电池寿命至少为1年;2. 价格低廉,产品零售价不超过9美元;3.具有很强的灵活性,能用多种语言精确地识别并合成与说话人相关的语音;4. 整个语音控制核产品应具备可复用的特性。 本文介绍利用Frontier Design公司设计工具来开发欧元兑换器ASIC产品的全过程。在ASIC中实现复杂DSP算法的要求通常极为苛刻,但采用Frontier的结构合成工具A|RT Designer工具能迅速优化RTL描述,该工具还允许自由选择备用结构以优化应用设计。 通过应用基于C语言的设计流,能在结构设计阶段对新特性进行设计和硬件优化,这能降低50%的硅片面积,通过加快 C语言原型硬件的设计,可以进一步扩展设计的性能以满足用户对产品规格的严格要求。 算法研究 欧元兑换器的效率在一定程度上取决于语音命令与存储数据库的比较以及执行命令的能力。开发出满足最终产品要求的算法对设计的成功至关重要,因为没有人希望看到语音控制设备不能始终如一地识别命令,人们需要算法自始至终达到98%以上的识别精度。因此,目前面临的难题包括检测并清除背景噪声、区分真实的命令字和其他噪声(呼吸声、微小静电干扰声及麦克风声响)、确定命令字的起始和终止以及将输入与存储的“声纹谱”数据库及随后的命令字识别(图1)进行比较。 以下几种先进的计算密集DSP算法适用于解决上述问题:1. Mel频率声谱(cepstral)系数(MFCC)算法,MFCC算法由快速傅立叶变换(FFT)功能谱、Mel定标和log ii构成;2. 反离散余弦变换(iDCT);3. 应用多重估计和选择算法连续识别并估计背景声音和语音噪声的连续噪声电平估计程序;4. 在命令字有效期间及其附近对声音能级实施详尽分析的不精确和精确命令字边界检测算法;5. 对一系列不等长度的向量进行比较并在这些向量间比较持续时间变化的动态时间扭曲算法(dynamic time warp)。 该算法用浮点C语言编程,为了调整并优化参数,浮点C代码的编译和仿真速度要足够快以检验算法的性能。最后,C语言代码必须能在传统的PC机上运行,语音识别和合成算法的性能可在实际环境中进行测试。最终的语音识别算法在450MHz奔腾机上测试,当用该公司的内部语音记录库进行测试时,可得到99%的识别精度。 [b]浮点算法向定点算法转换 [/b] 芯片实现需要将浮点算法转换为定点算法,要保证动态范围和精度并防止转换后超越动态极限。常规定点操作数的非优化范围可能导致操作数绕回(wrap around, 如(max+1)得到(min)),并引发严重的削波和误码。定点的精确度同等重要,特别是在重复的信号处理运算中。当精确度不够时,重复的信号处理算法将导致故障传播和错误累积,最终信号可能逐渐退化成白噪声,这对于语音控制产品来说无疑是灾难性的错误。 Frontier工具拥有一个称为A|RT库的C++类库,它是分析C代码定点性能的工具。该类库支持多种定点数据类型,对多重溢出行为(如饱和和绕回)提供位真建模(bit-true modeling),并提供截断和舍入零等多重量化模型。原始的32位浮点语音识别算法支持数据以8 KHz输入,其典型信号带宽为32位,内存容量要求为几千字节,典型语音用户接口的输出以每秒几字节的速率测量。 代码合并实现最终产品 分析表明,全局数据类型(global data-type)和数组只需16位(1个符号位,10个动态位,5个精度位)就足以保持算法的精度,而不会产生噪声。但是,高度重复性的FFT子程序需要8个动态位、7个精度位以及1个符号位。通常这种分析可用全局使用的19位字宽满足任何操作的动态位和精度位的最大要求。由于A|RT库允许字宽动态改变,而全局数据类型定义了1个符号位、10个动态位和5个精度位,FFT的MAC结果分配了1个符号位、8个动态位和5个精度位,因此设计的字宽(包括总线)保持为16位。这样可大大节省硅片面积。 完成定点C算法转换后,就可用常规C++编译器编译C代码,并在PC机上运行(也可在HP或SUN机器上运行)。所有信号的位真定义(bit-true definition)保证了硬件映射的正确索引以及到其他数字部件如HDL编译器和仿真器的直接接口。将定点识别代码与欧元兑换器应用程序的C代码合并,就可得到完整的可执行最终代码。 系统设计的考虑 为了达到成本目标,单片SoC解决方案是唯一可行的方案。SoC必须将如下资源集成至不超过25,000门的芯片上:1. 语音识别与合成(SRS)识别核;2. 语音识别与合成(SRS)程序和欧元兑换器代码(最大30KB);3. 语音合成实例(最大30KB);4. 用于存储声纹(voice print)并用作中间结果存储器的RAM(最大30K字节);5. AD/DA转换器;6. 麦克风接口;7. 扬声器接口。 功耗也是要考虑的重要问题,电池寿命至少应为1年半。要满足这些苛刻的功率要求,系统必须具备省电模式、在RAM中存储声纹、处理器具有较低的时钟频率以及高效率的音频放大器。 SRS处理器结构 要给定所必需的处理和低功耗约束条件,选择目标时钟频率是首要任务。根据对初始功耗和处理计算的估计,我们认为2到4MHz时钟频率足以满足要求。选择3.579 MHz是因为该频率是NTSC视频系统的基础,而石英成本低廉。 该算法需要检测并去除背景噪声。为了从奔腾机的450MHz时钟得到3.5MHz时钟,并保持芯片核门数小于25,000,SRS要采用专用结构。 设计专用处理器费时费力,要用HDL语言重写算法以获得最佳方案。A|RT Designer工具综合了基于控制器的结构,并直接以高效能的C语言算法为基础。设计工程师通过分析和优化,然后转化为Verilog或VHDL代码。 设计工程师使用A|RT Designer工具为语音识别算法合成适当的结构,之后进行RTL描述。该工具分配必需的数据通路资源(乘法器、加法器、ALU、I/O、RAM、ROM等),为这些资源分配算术运算,并对运算过程进行调度。同时将自动生成一个控制器、微代码(用来控制资源分配和调度)及寄存器、多路转换器和总线。 将SRS算法映射到硬件结构的关键参数是:以3.5MHz目标时钟频率运行完整的SRS代码,且不超过最大25,000门的约束条件。使用A|RT Designer的“负载视图(load view)”,设计工程师识别出代表性能瓶颈的几个多周期运算(multiple cycle operation)。视图上出现瓶颈的位置将显示相关C代码,设计工程师因而能识别产生瓶颈的原因并试验备选解决方案。 最明显的瓶颈是MEL运算中的密集FFT计算,它占据了实时处理周期80%的时间。通过增加一个二级加法器和专用地址计算单元ACU (address calculation unit),FFT就能优化到只占原始运算周期的10%。这虽然增加了硬件设备,但付出的代价只是4,000个门,正好在硬件预算以内。即便如此改进,所用周期的总数目实在太高,难以达到3.5MHz的时钟频率。 进一步分析表明,可以改进对数函数的计算。当在RISC DSP (NSC CR16B)上运行C语言算法时,该运算占用大约1,000个周期,约为实时运算需求的15%。添加专用的特定应用单元ASU (application specific unit)进一步将这些功能的循环周期降至3个周期,而只增加200个门。上述结构上的改变使最小时钟频率为1.5MHz,少于目标频率的一半。 对门电路数目和语音识别核功耗的优化可以降低寄存器触发器的数目。触发器的开销很大(每个需要10个门电路),并消耗很大的功率。A|RT Designer的“寿命视图(life-time view)”用来分析组成每个变量寿命的周期数目及变量被使用的频率。通过在RAM中存储不常使用但长期有效的变量,即可降低寄存器的总数,进一步减小所需的硅片面积和功率。该措施节约了50%的寄存器门电路,同时为运算周期预算留下充足的开销空间。 RAM压缩的实现 在设计初期,我们已经明确30KB的RAM空间太紧张。参考SRS C代码的每个声纹谱(约为1秒钟的语音)字占用大约1-2KB,相当于30条命令,这样几乎没给中间结果SRAM留下任何空间。由于30KB的RAM占用了硅片相当大的面积,因此在硅片预算中无法添加更多的RAM(图2)。 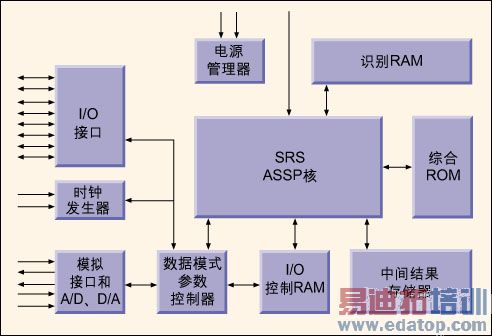 整个芯片使用标准的0.35μm CMOS工艺制造,解决RAM空间问题的唯一解决方案是采用某些形式的语音压缩。 声纹数据可用两种方法压缩:无损压缩或有损压缩。目前存在几种以现有的标准C代码源程序为基础,用C语言实现的无损压缩方法。声纹采样数据可用作参考,最佳的无损算法可得到30%的压缩率。采用有损压缩,还能再压缩20%,并且不明显降低识别质量。有损压缩完全可以缩放,从而获得依赖于实际声纹长度或词汇表大小的可变压缩率。由此得到的C代码算法共500行,并对声纹得到50%的压缩率。下一步就可以集成语音压缩和语音识别IP块了。 然后只需将这500行代码与10,000行SRS代码合并,得到一个新功能子程序,在存储声纹或读取RAM中的声纹时调用。但程序的计算量相当大,初始计算后约需要150万个时钟周期,这与SRS处理所需的时间相当。幸运地是,有效时钟频率留出的近2.5 MHz能解决这个进程问题,而无需进一步优化。此压缩方案将RAM需求降低到20-25KB,留出至少5KB用于处理器的中间结果存储器之用。 扬声器接口的实现 单电池电源管理偏置网络、数模转换器(DAC)和模拟放大器的要占用较大的芯片面积,而直接用C语言实现脉宽调制(PWM)扬声器驱动程序可以解决这个问题。 扬声器如何发音?C代码可使用该公司的A|RT Builder “C-到-HDL”转换工具直接转换为VHDL。然后使用Exemplar的Leonardo Spectrum加以合成,并映射到Xilinx的Virtex FPGA,采用Xilinx FPGA主板,就能将扬声器同2个数字输出直接相连,启动开关,即可测听音效了。 RTL描述的生成 当工程人员对语音识别SoC的性能和结构感到满意时,就可使用A|RT Designer工具自动生成用于最终硅片的RTL VHDL语言描述。该工具自动为控制器生成RTL代码及微代码、RAM、ROM和数据通路功能。另外A|RT Designer工具在设计流的每个阶段自动生成测试基准,因此原始的浮点算法仿真可与浮点C和HDL方案中的仿真媲美。VHDL仿真与原始的浮点C代码严格对应,这意味着SoC具有与浮点算法相同的精度。 最终结构 SRS ASIC所需的全部功能都集成在单芯片上(图2)。另外所有为该SoC开发的IP都可复用。SRS算法目前应用于CR16B RISC核的DECT电话语音识别器上。数据压缩功能也可复用,以进一步增强专用可变位率ADPCM音频压缩代码(VADPCM)。VADPCM同样可用于SRS核,在不利用模拟元件的条件下,PWM算法及方案仍然能实现高品质的音频输出。SRS实现方案本身在下一代产品中还可以修改。
整个芯片使用标准的0.35μm CMOS工艺制造,解决RAM空间问题的唯一解决方案是采用某些形式的语音压缩。 声纹数据可用两种方法压缩:无损压缩或有损压缩。目前存在几种以现有的标准C代码源程序为基础,用C语言实现的无损压缩方法。声纹采样数据可用作参考,最佳的无损算法可得到30%的压缩率。采用有损压缩,还能再压缩20%,并且不明显降低识别质量。有损压缩完全可以缩放,从而获得依赖于实际声纹长度或词汇表大小的可变压缩率。由此得到的C代码算法共500行,并对声纹得到50%的压缩率。下一步就可以集成语音压缩和语音识别IP块了。 然后只需将这500行代码与10,000行SRS代码合并,得到一个新功能子程序,在存储声纹或读取RAM中的声纹时调用。但程序的计算量相当大,初始计算后约需要150万个时钟周期,这与SRS处理所需的时间相当。幸运地是,有效时钟频率留出的近2.5 MHz能解决这个进程问题,而无需进一步优化。此压缩方案将RAM需求降低到20-25KB,留出至少5KB用于处理器的中间结果存储器之用。 扬声器接口的实现 单电池电源管理偏置网络、数模转换器(DAC)和模拟放大器的要占用较大的芯片面积,而直接用C语言实现脉宽调制(PWM)扬声器驱动程序可以解决这个问题。 扬声器如何发音?C代码可使用该公司的A|RT Builder “C-到-HDL”转换工具直接转换为VHDL。然后使用Exemplar的Leonardo Spectrum加以合成,并映射到Xilinx的Virtex FPGA,采用Xilinx FPGA主板,就能将扬声器同2个数字输出直接相连,启动开关,即可测听音效了。 RTL描述的生成 当工程人员对语音识别SoC的性能和结构感到满意时,就可使用A|RT Designer工具自动生成用于最终硅片的RTL VHDL语言描述。该工具自动为控制器生成RTL代码及微代码、RAM、ROM和数据通路功能。另外A|RT Designer工具在设计流的每个阶段自动生成测试基准,因此原始的浮点算法仿真可与浮点C和HDL方案中的仿真媲美。VHDL仿真与原始的浮点C代码严格对应,这意味着SoC具有与浮点算法相同的精度。 最终结构 SRS ASIC所需的全部功能都集成在单芯片上(图2)。另外所有为该SoC开发的IP都可复用。SRS算法目前应用于CR16B RISC核的DECT电话语音识别器上。数据压缩功能也可复用,以进一步增强专用可变位率ADPCM音频压缩代码(VADPCM)。VADPCM同样可用于SRS核,在不利用模拟元件的条件下,PWM算法及方案仍然能实现高品质的音频输出。SRS实现方案本身在下一代产品中还可以修改。
新加坡Columns公司在便携式语音控制产品应用中起步较早,其中一个产品是执行欧元与其他欧洲货币之间进行兑换的“语音控制欧洲货币兑换器”。欧元兑换器的设计要求包括:1. 功率小,电池寿命至少为1年;2. 价格低廉,产品零售价不超过9美元;3.具有很强的灵活性,能用多种语言精确地识别并合成与说话人相关的语音;4. 整个语音控制核产品应具备可复用的特性。 本文介绍利用Frontier Design公司设计工具来开发欧元兑换器ASIC产品的全过程。在ASIC中实现复杂DSP算法的要求通常极为苛刻,但采用Frontier的结构合成工具A|RT Designer工具能迅速优化RTL描述,该工具还允许自由选择备用结构以优化应用设计。 通过应用基于C语言的设计流,能在结构设计阶段对新特性进行设计和硬件优化,这能降低50%的硅片面积,通过加快 C语言原型硬件的设计,可以进一步扩展设计的性能以满足用户对产品规格的严格要求。 算法研究 欧元兑换器的效率在一定程度上取决于语音命令与存储数据库的比较以及执行命令的能力。开发出满足最终产品要求的算法对设计的成功至关重要,因为没有人希望看到语音控制设备不能始终如一地识别命令,人们需要算法自始至终达到98%以上的识别精度。因此,目前面临的难题包括检测并清除背景噪声、区分真实的命令字和其他噪声(呼吸声、微小静电干扰声及麦克风声响)、确定命令字的起始和终止以及将输入与存储的“声纹谱”数据库及随后的命令字识别(图1)进行比较。 以下几种先进的计算密集DSP算法适用于解决上述问题:1. Mel频率声谱(cepstral)系数(MFCC)算法,MFCC算法由快速傅立叶变换(FFT)功能谱、Mel定标和log ii构成;2. 反离散余弦变换(iDCT);3. 应用多重估计和选择算法连续识别并估计背景声音和语音噪声的连续噪声电平估计程序;4. 在命令字有效期间及其附近对声音能级实施详尽分析的不精确和精确命令字边界检测算法;5. 对一系列不等长度的向量进行比较并在这些向量间比较持续时间变化的动态时间扭曲算法(dynamic time warp)。 该算法用浮点C语言编程,为了调整并优化参数,浮点C代码的编译和仿真速度要足够快以检验算法的性能。最后,C语言代码必须能在传统的PC机上运行,语音识别和合成算法的性能可在实际环境中进行测试。最终的语音识别算法在450MHz奔腾机上测试,当用该公司的内部语音记录库进行测试时,可得到99%的识别精度。 [b]浮点算法向定点算法转换 [/b] 芯片实现需要将浮点算法转换为定点算法,要保证动态范围和精度并防止转换后超越动态极限。常规定点操作数的非优化范围可能导致操作数绕回(wrap around, 如(max+1)得到(min)),并引发严重的削波和误码。定点的精确度同等重要,特别是在重复的信号处理运算中。当精确度不够时,重复的信号处理算法将导致故障传播和错误累积,最终信号可能逐渐退化成白噪声,这对于语音控制产品来说无疑是灾难性的错误。 Frontier工具拥有一个称为A|RT库的C++类库,它是分析C代码定点性能的工具。该类库支持多种定点数据类型,对多重溢出行为(如饱和和绕回)提供位真建模(bit-true modeling),并提供截断和舍入零等多重量化模型。原始的32位浮点语音识别算法支持数据以8 KHz输入,其典型信号带宽为32位,内存容量要求为几千字节,典型语音用户接口的输出以每秒几字节的速率测量。 代码合并实现最终产品 分析表明,全局数据类型(global data-type)和数组只需16位(1个符号位,10个动态位,5个精度位)就足以保持算法的精度,而不会产生噪声。但是,高度重复性的FFT子程序需要8个动态位、7个精度位以及1个符号位。通常这种分析可用全局使用的19位字宽满足任何操作的动态位和精度位的最大要求。由于A|RT库允许字宽动态改变,而全局数据类型定义了1个符号位、10个动态位和5个精度位,FFT的MAC结果分配了1个符号位、8个动态位和5个精度位,因此设计的字宽(包括总线)保持为16位。这样可大大节省硅片面积。 完成定点C算法转换后,就可用常规C++编译器编译C代码,并在PC机上运行(也可在HP或SUN机器上运行)。所有信号的位真定义(bit-true definition)保证了硬件映射的正确索引以及到其他数字部件如HDL编译器和仿真器的直接接口。将定点识别代码与欧元兑换器应用程序的C代码合并,就可得到完整的可执行最终代码。 系统设计的考虑 为了达到成本目标,单片SoC解决方案是唯一可行的方案。SoC必须将如下资源集成至不超过25,000门的芯片上:1. 语音识别与合成(SRS)识别核;2. 语音识别与合成(SRS)程序和欧元兑换器代码(最大30KB);3. 语音合成实例(最大30KB);4. 用于存储声纹(voice print)并用作中间结果存储器的RAM(最大30K字节);5. AD/DA转换器;6. 麦克风接口;7. 扬声器接口。 功耗也是要考虑的重要问题,电池寿命至少应为1年半。要满足这些苛刻的功率要求,系统必须具备省电模式、在RAM中存储声纹、处理器具有较低的时钟频率以及高效率的音频放大器。 SRS处理器结构 要给定所必需的处理和低功耗约束条件,选择目标时钟频率是首要任务。根据对初始功耗和处理计算的估计,我们认为2到4MHz时钟频率足以满足要求。选择3.579 MHz是因为该频率是NTSC视频系统的基础,而石英成本低廉。 该算法需要检测并去除背景噪声。为了从奔腾机的450MHz时钟得到3.5MHz时钟,并保持芯片核门数小于25,000,SRS要采用专用结构。 设计专用处理器费时费力,要用HDL语言重写算法以获得最佳方案。A|RT Designer工具综合了基于控制器的结构,并直接以高效能的C语言算法为基础。设计工程师通过分析和优化,然后转化为Verilog或VHDL代码。 设计工程师使用A|RT Designer工具为语音识别算法合成适当的结构,之后进行RTL描述。该工具分配必需的数据通路资源(乘法器、加法器、ALU、I/O、RAM、ROM等),为这些资源分配算术运算,并对运算过程进行调度。同时将自动生成一个控制器、微代码(用来控制资源分配和调度)及寄存器、多路转换器和总线。 将SRS算法映射到硬件结构的关键参数是:以3.5MHz目标时钟频率运行完整的SRS代码,且不超过最大25,000门的约束条件。使用A|RT Designer的“负载视图(load view)”,设计工程师识别出代表性能瓶颈的几个多周期运算(multiple cycle operation)。视图上出现瓶颈的位置将显示相关C代码,设计工程师因而能识别产生瓶颈的原因并试验备选解决方案。 最明显的瓶颈是MEL运算中的密集FFT计算,它占据了实时处理周期80%的时间。通过增加一个二级加法器和专用地址计算单元ACU (address calculation unit),FFT就能优化到只占原始运算周期的10%。这虽然增加了硬件设备,但付出的代价只是4,000个门,正好在硬件预算以内。即便如此改进,所用周期的总数目实在太高,难以达到3.5MHz的时钟频率。 进一步分析表明,可以改进对数函数的计算。当在RISC DSP (NSC CR16B)上运行C语言算法时,该运算占用大约1,000个周期,约为实时运算需求的15%。添加专用的特定应用单元ASU (application specific unit)进一步将这些功能的循环周期降至3个周期,而只增加200个门。上述结构上的改变使最小时钟频率为1.5MHz,少于目标频率的一半。 对门电路数目和语音识别核功耗的优化可以降低寄存器触发器的数目。触发器的开销很大(每个需要10个门电路),并消耗很大的功率。A|RT Designer的“寿命视图(life-time view)”用来分析组成每个变量寿命的周期数目及变量被使用的频率。通过在RAM中存储不常使用但长期有效的变量,即可降低寄存器的总数,进一步减小所需的硅片面积和功率。该措施节约了50%的寄存器门电路,同时为运算周期预算留下充足的开销空间。 RAM压缩的实现 在设计初期,我们已经明确30KB的RAM空间太紧张。参考SRS C代码的每个声纹谱(约为1秒钟的语音)字占用大约1-2KB,相当于30条命令,这样几乎没给中间结果SRAM留下任何空间。由于30KB的RAM占用了硅片相当大的面积,因此在硅片预算中无法添加更多的RAM(图2)。 整个芯片使用标准的0.35μm CMOS工艺制造,解决RAM空间问题的唯一解决方案是采用某些形式的语音压缩。 声纹数据可用两种方法压缩:无损压缩或有损压缩。目前存在几种以现有的标准C代码源程序为基础,用C语言实现的无损压缩方法。声纹采样数据可用作参考,最佳的无损算法可得到30%的压缩率。采用有损压缩,还能再压缩20%,并且不明显降低识别质量。有损压缩完全可以缩放,从而获得依赖于实际声纹长度或词汇表大小的可变压缩率。由此得到的C代码算法共500行,并对声纹得到50%的压缩率。下一步就可以集成语音压缩和语音识别IP块了。 然后只需将这500行代码与10,000行SRS代码合并,得到一个新功能子程序,在存储声纹或读取RAM中的声纹时调用。但程序的计算量相当大,初始计算后约需要150万个时钟周期,这与SRS处理所需的时间相当。幸运地是,有效时钟频率留出的近2.5 MHz能解决这个进程问题,而无需进一步优化。此压缩方案将RAM需求降低到20-25KB,留出至少5KB用于处理器的中间结果存储器之用。 扬声器接口的实现 单电池电源管理偏置网络、数模转换器(DAC)和模拟放大器的要占用较大的芯片面积,而直接用C语言实现脉宽调制(PWM)扬声器驱动程序可以解决这个问题。 扬声器如何发音?C代码可使用该公司的A|RT Builder “C-到-HDL”转换工具直接转换为VHDL。然后使用Exemplar的Leonardo Spectrum加以合成,并映射到Xilinx的Virtex FPGA,采用Xilinx FPGA主板,就能将扬声器同2个数字输出直接相连,启动开关,即可测听音效了。 RTL描述的生成 当工程人员对语音识别SoC的性能和结构感到满意时,就可使用A|RT Designer工具自动生成用于最终硅片的RTL VHDL语言描述。该工具自动为控制器生成RTL代码及微代码、RAM、ROM和数据通路功能。另外A|RT Designer工具在设计流的每个阶段自动生成测试基准,因此原始的浮点算法仿真可与浮点C和HDL方案中的仿真媲美。VHDL仿真与原始的浮点C代码严格对应,这意味着SoC具有与浮点算法相同的精度。 最终结构 SRS ASIC所需的全部功能都集成在单芯片上(图2)。另外所有为该SoC开发的IP都可复用。SRS算法目前应用于CR16B RISC核的DECT电话语音识别器上。数据压缩功能也可复用,以进一步增强专用可变位率ADPCM音频压缩代码(VADPCM)。VADPCM同样可用于SRS核,在不利用模拟元件的条件下,PWM算法及方案仍然能实现高品质的音频输出。SRS实现方案本身在下一代产品中还可以修改。