- 易迪拓培训,专注于微波、射频、天线设计工程师的培养
HFSS15: Discussion of HFSS Distributed Memory Solutions
录入:edatop.com 点击:
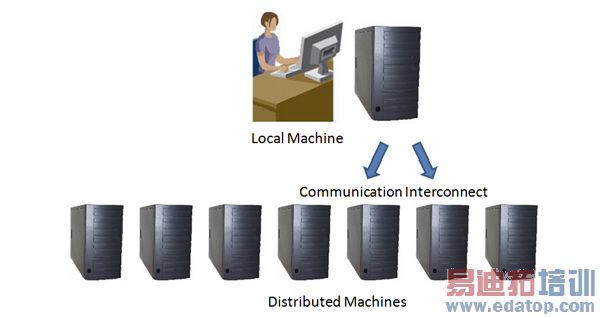
Each machine or "compute node" is connected to the other nodes via a "communication interconnect" and relies on the message passing library (MPI) to exchange data and synchronize computational tasks. Ethernet, Myrinet and Infiniband are common communication interconnects. Each node is identified by a unique integer ID or rank number. The local machine is known as the "Rank-0 node" and is the master. The Rank-0 machine has many tasks including:
• Management of all communication with the HFSS user interface. None of the distributed machines communicate directly with the user interface but pass all information through the Rank-0 machine.
• Mesh generation. The mesh is generated only on the Rank-0 machine.
• Disk access. None of the distributed machines access their local discs. The simulation mesh, intermediate and solution data are passed to and from the distributed machines using MPI.
• Distribution and control of computational tasks on the distributed machines. The simulation process is dynamic and the Rank-0 machine will determine which of the distributed machines has memory available to distribute tasks accordingly.
• Post-processing of the HFSS Distributed Memory Solution
The algorithms used in the distributed memory version of the HFSS solver engine resemble those used in the non-distributed memory version. The matrix solution algorithms in the distributed memory version of HFSS have been adjusted to use slightly more memory so that larger problems can be simulated in less time.
The MPI enabled HFSS solver engine is not multithreaded. (The regular HFSS engine is multithreaded.) If a particular machine has multiple cores and enough memory you can define this machine several times in the distributed machine list ("doubling up") to take advantage of the extra cores. Certain portions of the MPI enabled HFSS solver will be multithreaded in the future.
During the "Matrix Assembly" and "Matrix Solve" steps of the solution process the HFSS engine attempts to distribute memory use evenly. At various points in the matrix solution process the software will poll the machines in the cluster and determine which machine has the most memory available and then reserve a block of memory on that machine. If a particular machine does not have a large block of memory available the memory use on that machine will grow only slowly. If none of the machines in the cluster have sufficient memory the solution process will terminate and an error message will be posted to the HFSS message window.
Many factors affect solution time. In general, the solution time will decrease as the number of compute nodes increases. However, parallel efficiency decreases as the ratio of communication to computation increases so to some extent you need to match the size of the problem to the size of parallel machine. Simulating small structures on a large cluster will not be efficient and may take longer and use significantly more memory than if the structure was simulated on a single machine.
Network interconnect speed and topology can affect performance significantly in homogenous clusters. Performance can degrade if machines are "doubled up" to the point of causing memory bus contention or if the cluster is significantly inhomogeneous and certain faster machines need to wait for slower machines to catch up to synchronization points in the solution process.

